
科技巨头公司—Google,在12月6日发表了新一代的人工智慧模型—Gemini,官方对外宣称,在32项AI测试中,有30项的评分超越了OpenAI的GPT-4。
官方秀出的展示视频中,与多模型人工智慧的互动,令社群媒体瞠目结舌,更被认为是辗压GPT-4的杀手级产品。然而没有想到的是,这场竞赛很快就迎来反转,Gemini似乎正在跌落神坛。
Google官方提前对影片进行了剪辑?
回顾谷歌的官方Youtube视频,首次展示的成果,已经展示了Google DeepMind AI实验室多年来在推理能力上的进步。这款新型智能模型能够预测一个纸球从塑料杯底部移动,或者在点连点图形成螃蟹之前,立即识别出它将成为螃蟹的形状,这种能力在其他人工智慧模型中是罕见的。
然而在视频发布后不久,大家却发现,几天以后,Google在视频下方的说明区里加了一段备注表示:
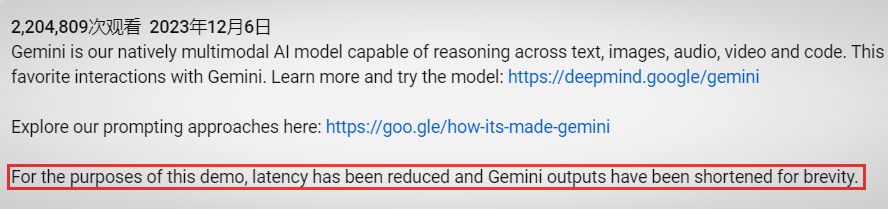
为了这次的演示,我们降低了反应延迟时间,并且简化了Gemini输出的内容长度,以便于简洁地展示。
这句话意味着每个与人工智慧的对谈过程中,所花费的时间实际上比视频中的时间要长,具体要等待Gemini的响应时间是多久,Google并没有公布。
发言人:语音互动完全不存在?
据彭博社的报导,实际上这部视频的演示既不是实时进行的,也不是用语音进行的。Google的一位发言人对彭博社说明,该视频是利用静态照片和文字提示制作而成。此外,他们还展示开发者是如何使用手部照片、绘画作品或其他物体来与Gemini进行互动。
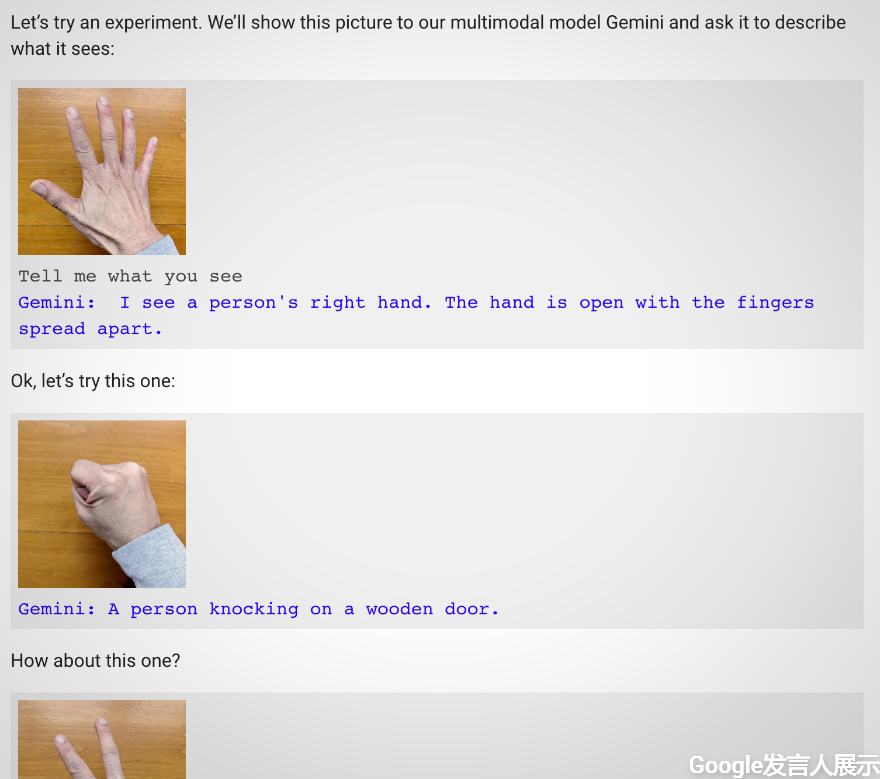
换句话说,演示中的声音,其实是在朗读人类制作给Gemini的提示,并向它展示静态图像。这与整部视频呈现的效果截然不同。目前社群媒体上的许多理解,皆是以为人们可以与Gemini进行流畅的语音对话,同时它能即时观察并响应周围环境,然而事实并非如此。
Google回应:为了激发开发者的灵感

值得一提的是,在AI产品的展示会上,不管是OpenAI、马斯克Grok,目前也都没有实际操作的演练,大部分都是截图或录像,因为AI输出的结果是不一定的,相同的参数与提示词,跑出来的结果可能都大不相同。对此,Gemini共同负责人Oriol Vinyals也发布推文,认为展示过程中并没有不正当的行为:
视频中所有的用户提示和输出都是真实的,只是为了简洁而缩短。这部视频展示了使用Gemini建立的多模式用户体验可能会是什么样子。我们制作这部视频是为了激发开发者的灵感。
从12月13日起,开发者和企业客户将能够通过Google AI Studio或Google Cloud Vertex AI中的Gemini API,存取Gemini Pro。
此外,Android开发人员也将能够使用Gemini Nano进行应用程序的开发和建置,到时候Gemini是否能够成为超越GPT-4的杀手级产品,正受全世界关注。









